

Venkatraman Balasubramanian
Orion Innovation
McKinsey Report suggests that Generative AI could unlock potential value of about 2.6 percent to 4.5 percent of annual revenues ($60 billion to $110 billion) annually on the pharmaceutical and medical product industry.
In this article, we look into the application of LLM to gather regulatory intelligence information from global regulations issued by multiple health authorities.
Regulatory strategists within regulatory affairs and submission managers with Regulatory Operations are always interested in keeping abreast of regulatory guidelines and changes that happen across the world in order to prepare for regulatory and submission strategies. These professionals look up health authority websites or scan publications or look into subscriptions such as Cortellis. Significant time and effort are spent in scanning these sources and summarizing regulatory guidelines, changes, etc., to define regulatory pathways and strategies and prepare submissions in compliance with health authority regulations. The intent of our initiative was to look into potential improvements in productivity around the search and retrieval of regulatory guidelines in order to speed up the filing and submission processes.
Quest for Answers
Following are some examples of the type of information these professionals are typically looking for:
- “What is the FDA’s position on AI in drug manufacturing?”
- “What are the requirements for registering a new drug application in Singapore?”
- “List FDA’s criteria for clinical trial protocol design to encourage diversity in clinical trials.”
- “Create a detailed checklist for licensing healthcare facilities in Bahrain.”
- “What are the new drug application requirements for a biologic in China?”
As part of our efforts to evaluate the application of LLM to regulatory use cases, we decided to apply LLMs to the extraction of regulatory intelligence either as summaries or Q&A responses from regulatory guidelines and other sources through a ChatGPT-like interface.
Methodology and Tools
During the early days of the ChatGPT announcement and subsequent investments by Microsoft into OpenAI, it was rather difficult to get hold of an Azure implementation of OpenAI due to heavy demand for the platform; instead, we had to experiment with several tools and technologies leveraging LLMs such as PrivateGPT, etc. Following were the different technologies we explored:

As an example, the figure below shows the prompt and response for one of the questions we had posed. There can be a series of prompts to understand the output better based on our needs.

- Highly Accurate (Contains the essence of the source document in its entirety)
- Accurate (Contains the essence of the source document with some details missing)
- Somewhat Accurate (Contains elements of the source document with significant details missing)
- Inaccurate (Contains only some aspects of the source document, with the majority of details missing)
- Totally Inaccurate (Does not contain any elements of the source document)
- No Response (Not enough information generated).
In early 2023, investigators at Vanderbilt who evaluated the accuracy and reliability of medical responses generated by ChatGPT submitted a research article to Nature. We have adopted some of the scoring methods used by this team. We also did a variation of the scoring on two different dimensions, namely accuracy and completeness on two different scales. The analysis of the two-dimensions approach will be presented at RSIDM 2024.
Data Analysis and Results
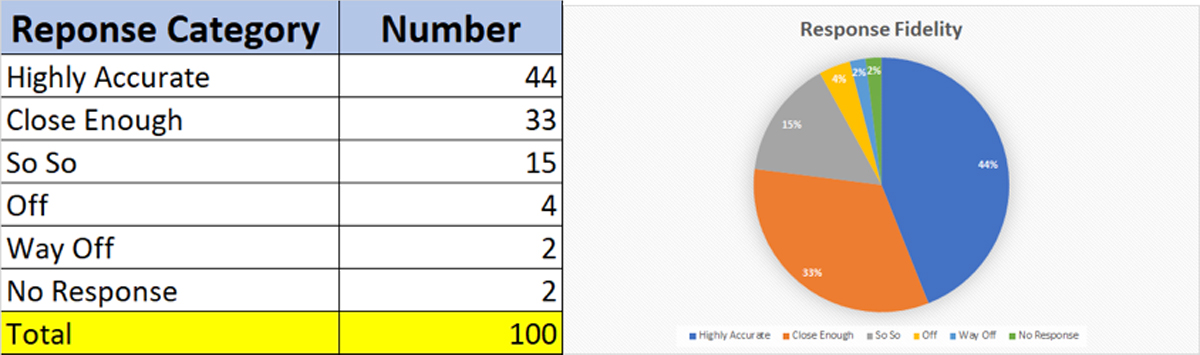
The table and graph below show the results of the scoring process across the different response categories. Close to 77 percent of responses were deemed accurate or close enough based on comparison of responses with the original source document, which is fairly good for a “search” exercise. This could potentially contribute to increased efficiencies while searching for regulatory guidances or updates. About 21 percent of the responses were not even close or were off.
We saw that a small number of questions did not have any responses. We believe that this is better than having “hallucinations.” A hallucination is when a Generative AI model generates inaccurate information as if it were correct. Hallucinations are often caused by limitations or biases in training data and algorithms, and can result in producing content that is wrong or even harmful. It is also possible that our limited sample of 100 source documents was not representative enough to see the phenomenon of hallucinations.
Discussion
Given that we had only 100 documents and 100 questions as a simplistic approach to this “experiment,” we could manually and fairly readily validate and verify the responses generated by GPT against the source documents. In the real world, this approach is not scalable given the volume of worldwide guidances and potential questions that may be asked. This experiment has raised more questions than answers:
- While 77 percent accuracy is a significant improvement in terms of productivity gains, the onus increases on the human subject matter expert to doubly make sure that the generated content is accurate and serves the underlying business needs.
- While it was possible to manually verify content for a small corpus of documents, is it realistic for regulatory professionals to validate and verify responses when the underlying corpus of knowledge is in the millions of documents?
- Can we use such an imprecise/incomplete approach to decision making, or do we use it only for narrowing down the search problem?
- Can we trust the summaries of regulatory intelligence that it gathered?
- How do we ensure repeatability when we use LLMs? Even between two runs of the same query at different times, the responses were slightly different, given that the repository is controlled and self-contained. How do we explain variations?
- How do we ensure explainability and referenceability? We fine-tuned the application to cite references for each output sentence but realized this can soon become overwhelming with each sentence having multiple citations within the source document. Is citation reference scalable?
- Are we less forgiving of machines than we are of humans?
Conclusions
GPT 3.5 generated largely accurate information (up to 77 percent) to natural language queries on a limited corpus of regulatory guidance documents from health authorities across the globe. However, based on our observations around explainability, repeatability, and referenceability, we conclude that we cannot simply rely solely on LLM output in terms of summaries or responses to queries related to regulatory intelligence. At best, LLMs can serve as copilots assisting in the search, retrieval, and summarization of regulatory guidelines and intelligence, requiring human oversight and review of generated responses. As rightly pointed out by the McKinsey article, “The increasing need to verify whether generated content is based on fact or inference elevates the need for a new level of quality control.” We are excited about the realm of possibilities to augment and automate existing approaches to gathering regulatory intelligence.
Acknowledgements
Assessment and evaluation of LLMs for regulatory use cases was carried out this summer by the Orion Innovation team. The author acknowledges the work of the team led by Asha Varadan along with our summer intern Akhil Krishnan Sunil (University of Buffalo) and the Orion India team: Vimal Srinivasan, Faizan Sheikh, Hemant More, and KL Harish.